数据仓库
OLTP
OLTP是联机事务处理的意思,主要是在业务运行中做的一些保障业务运行的事物处理工作,单个处理的时间比较快,常用在RDBMS也就是关系型数据库中
OLAP
数据仓库就是典型的联机分析系统,是一个面向分析,支持分析的系统
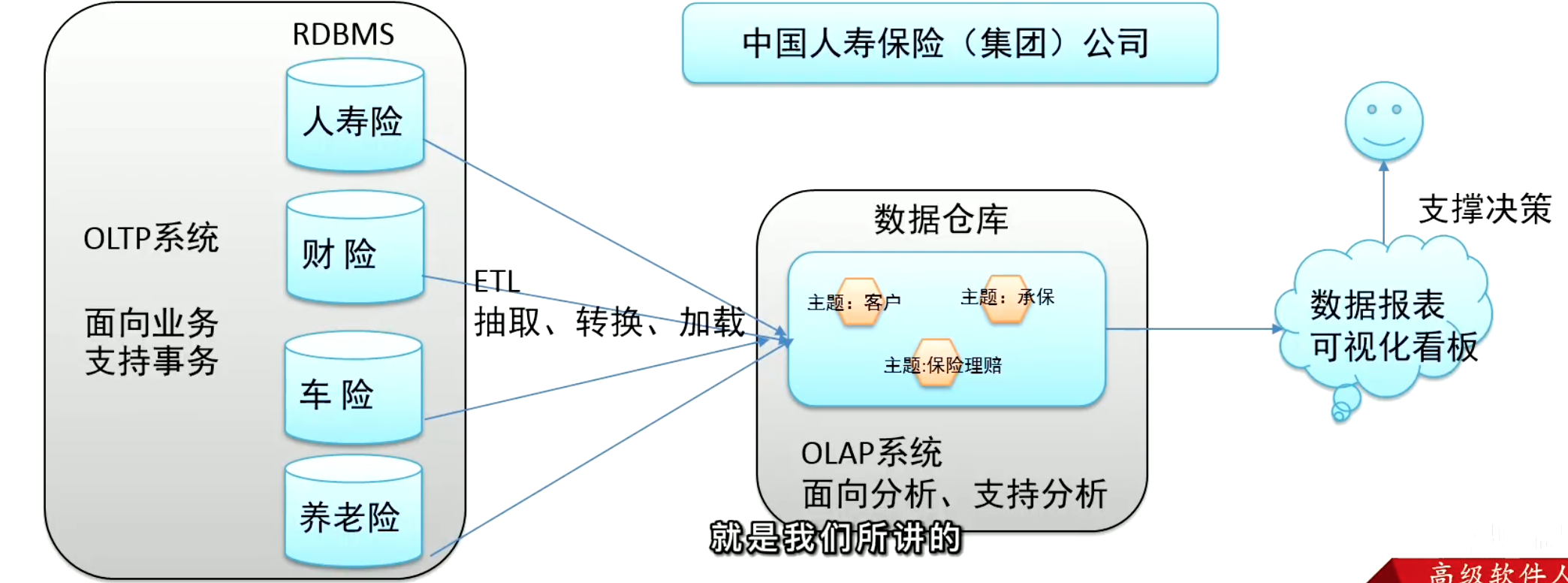
数据仓库(Data Warehouse简称数仓、DW )是一个用于储存、分析、报告的数据系统,目的是构建面向分析的集成化数据环境,分析结果为企业提供给决策支持。
数仓数据由外部来,不生产也不消费数据,数据来源于外部系统,结果开放给外部应用,所以叫数据仓库而不叫数据工厂。
关键特点
- 面向主题:主题是一个抽象的概念,是较高层次上的数据综合、归类进行分析利用的抽象(其实就是主题域)
- 集成性:不产生数据、从不同系统中集成来(抽取转换加载)
- 非易失性:是分析数据的平台,不是创造数据的平台
- 数据仓库是分析数据,不是创造数据,数据进入数据仓库中稳定且不会改变
- 数据仓库反应的是相当长一段时间内历史数据的内容,数仓用户对数据的操作大多是数据查询或比较复杂的挖掘
- 数据仓库中一般有大量的查询操作,但修改和删除操作很少
- 时变性:数据仓库的数据需要随着时间更新
Hive - 离线数仓
Hive是一款开源的数据仓库系统,由Facebook实现并开源。
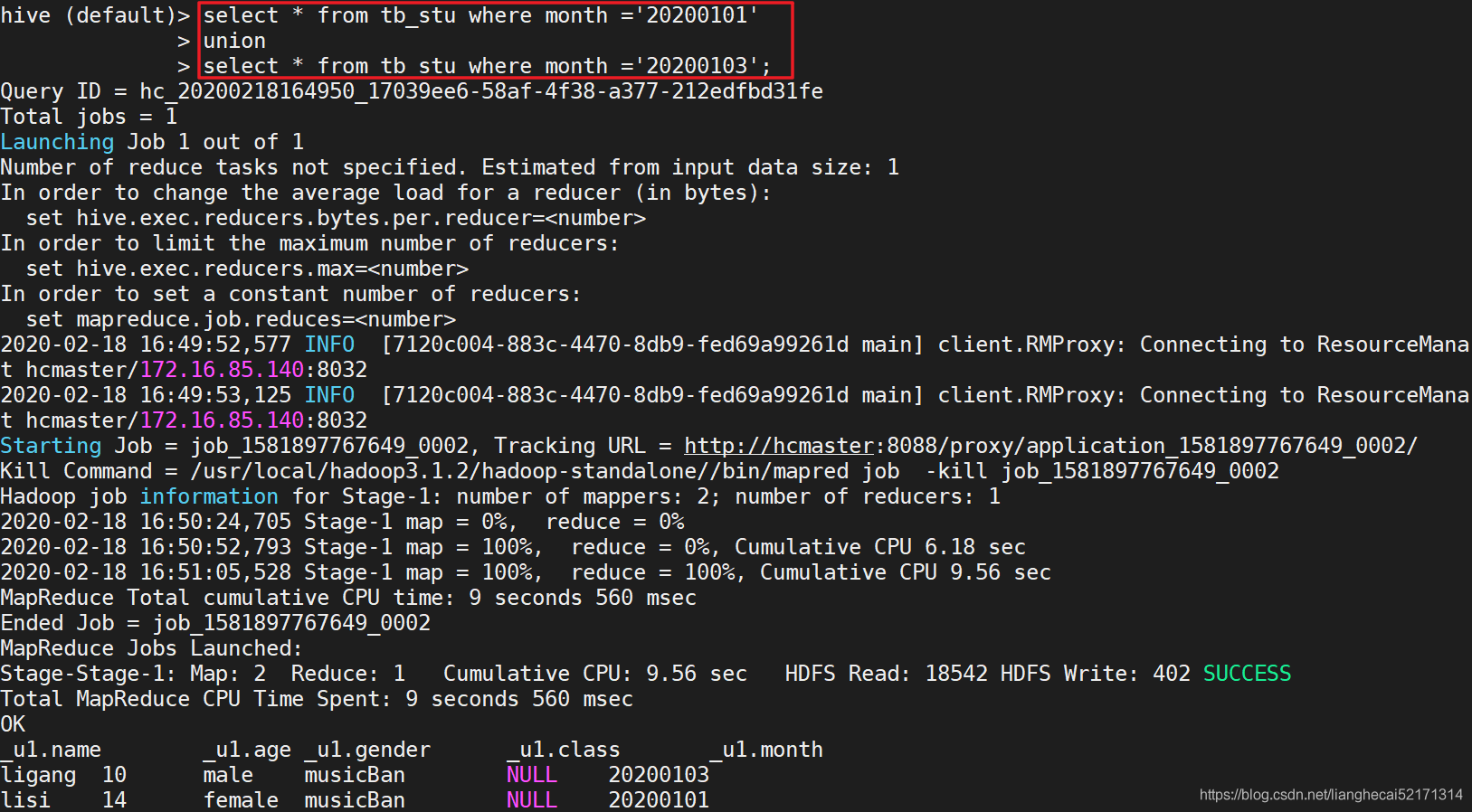
一条如下的分析语句
1 | SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age; |

可以转化为MR程序
<2, 25> ,1> ==<2, 25> ,<1,1>>=<2, 25> ,2>
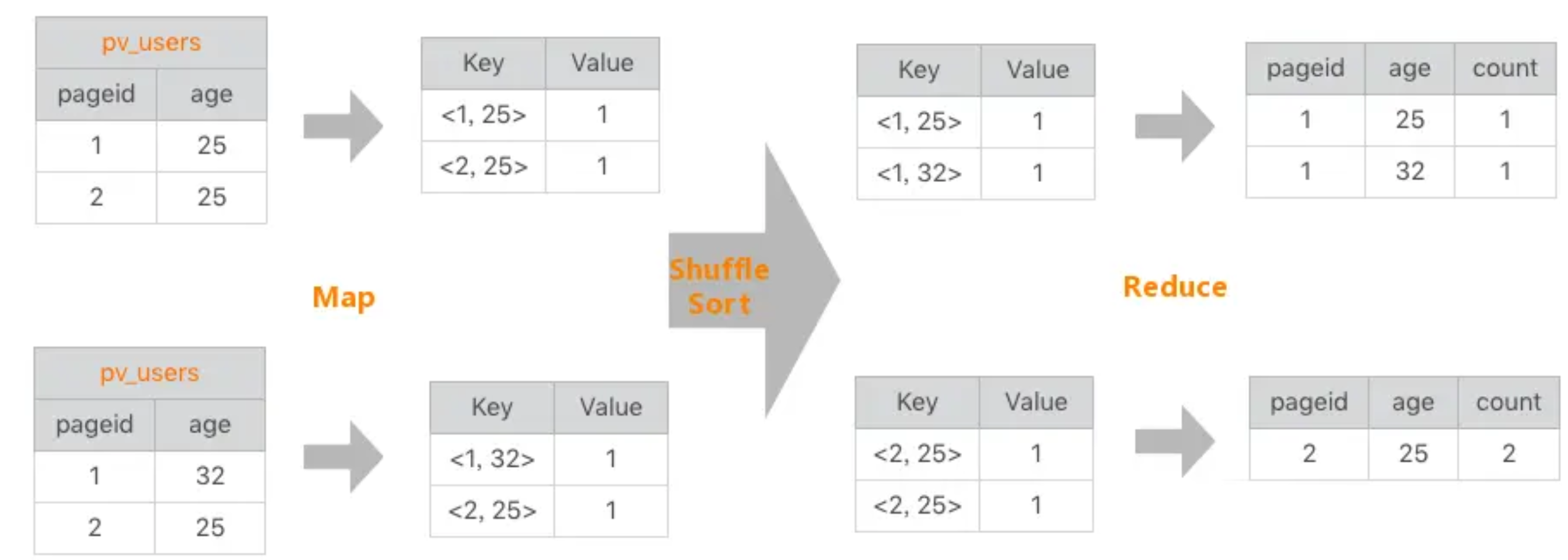
这样一条SQL就被简单的MapReduce计算过程处理好了
在数据仓库中,SQL是最常用的分析工具,这样一条SQL可以通过MapReduce程序实现,那么有没有工具能够自动将SQL生成MapReduce代码呢;这样只要数据分析师输入SQL,就可以自动生成MapReduce可执行的代码,然后提交Hadoop执行。这样一个神奇的工具就是Hadoop大数据仓库Hive。
Hive能直接处理输入的语句,调用MapReduce框架完成数据分析操作
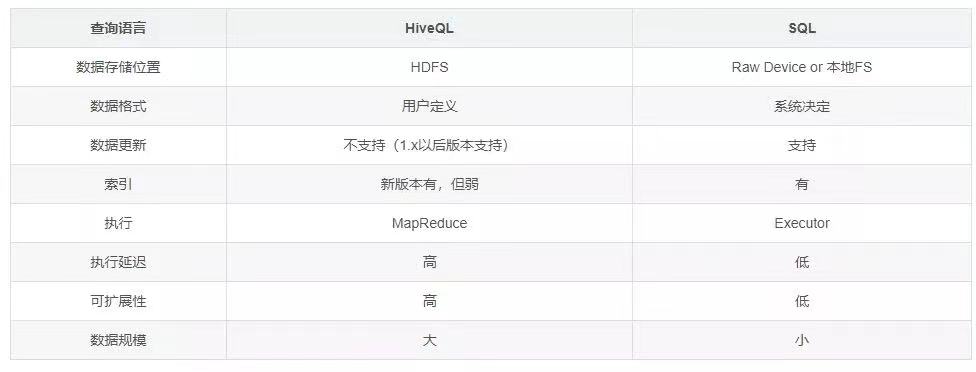
Hive与传统数据库比较
Hadoop和Hive的关系
数据仓库至少要具备储存和分析数据的能力,Hive利用HDFS储存数据,利用MapReduce查询分析数据,用户编写HQL转换为MR程序完成对数据的分析。
关键结构
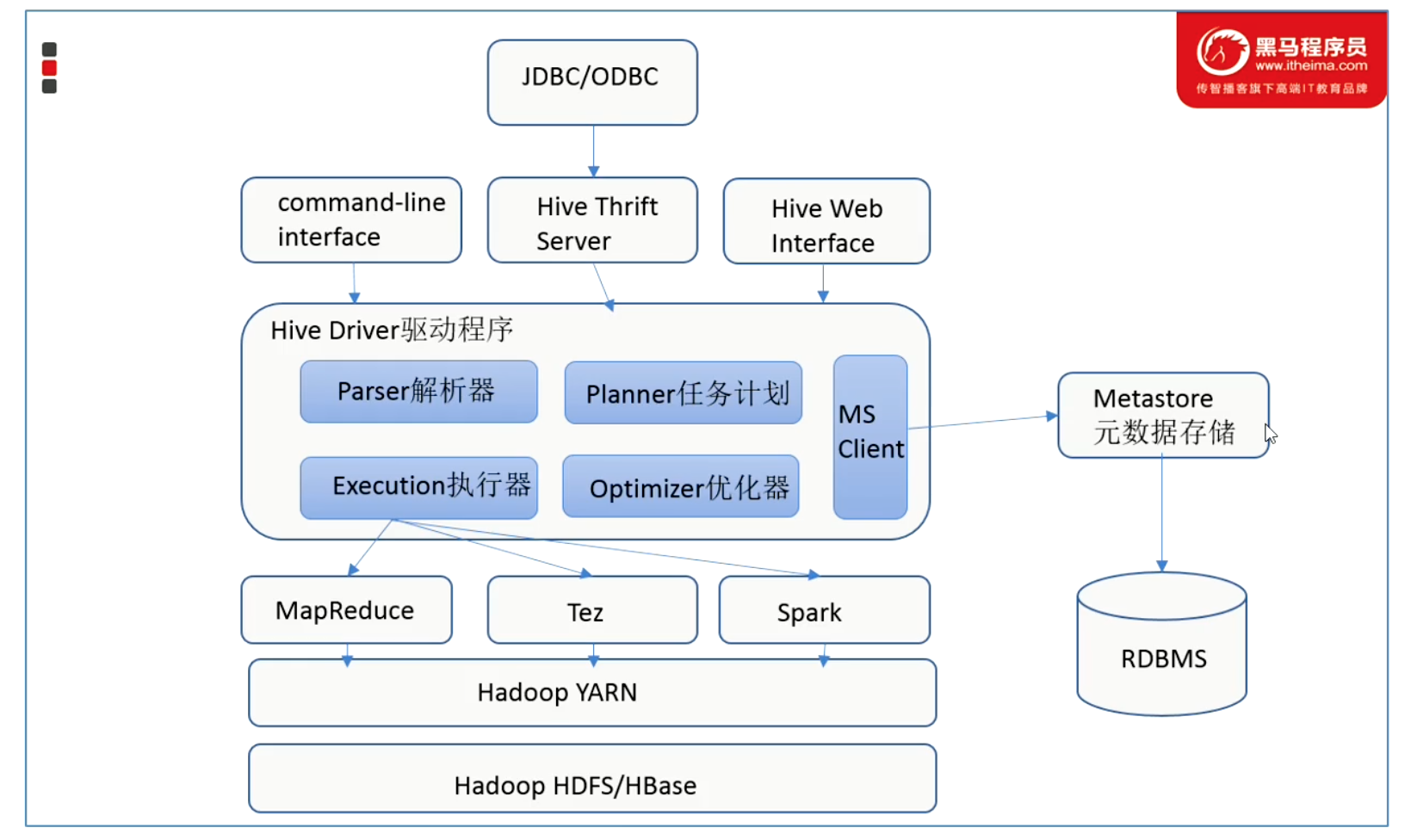
用户接口
包括cli、jdbc、webui
元数据存储(MetaStore也可以称为元数据服务)
表和文件之间的映射关系。hive存在derby中,也可以存在mysql中。安装时在配置文件中指定mysql地址;metastore是hive元数据的集中存放地。metastore默认使用内嵌的derby数据库作为存储引擎Derby引擎的缺点:一次只能打开一个会话使用MySQL作为外置存储引擎,可以多用户同时访问
Driver驱动程序
包括语法解析器,计划编译器,优化器,执行器
执行引擎
当下hive支持MapReduce、Tez、Spark 3种引擎
MetaStore安装模式
| 内嵌模式 | 本地模式 | 远程模式 | |
|---|---|---|---|
| MetaStore单独配置、启动 | 否 | 否 | 是 |
| Metadata储存介质 | Derby | Mysql | Mysql |
远程模式部署后的关系图.hive本身是单机,但通过依赖的组件实现了其分布式的能力
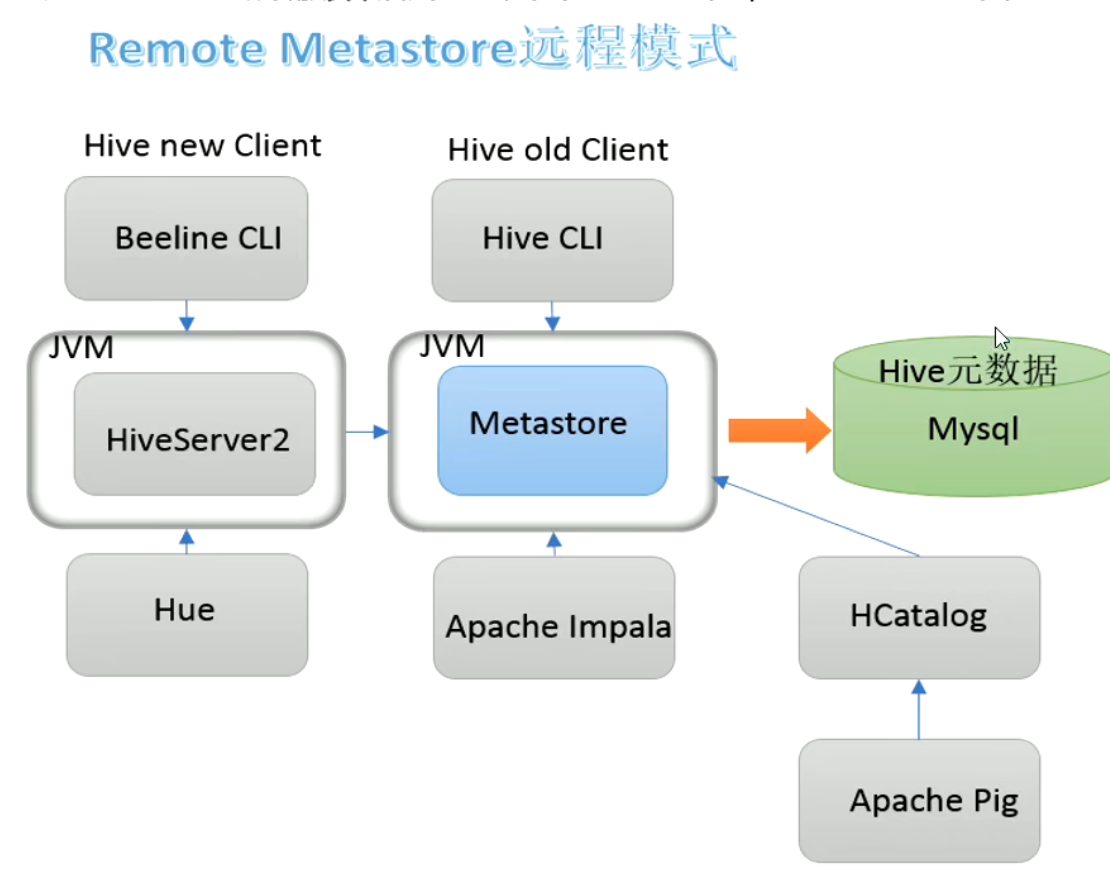
Beeline客户端首先会访问HiveServer2服务,所以需要启动Hive Server2
第三方推荐客户端:DataGrip,或者jetbrain自带的其他数据库连接
我们向Hive 提交SQL命令,如果是创建数据表的DDL,Hive就会通过执行引擎Driver将数据表的信息记录在MetaStore中。如果提交是的分析查询语句DQL,Driver就会讲该语句提交给编译器进行语法分析,最后生成一个MR执行计划
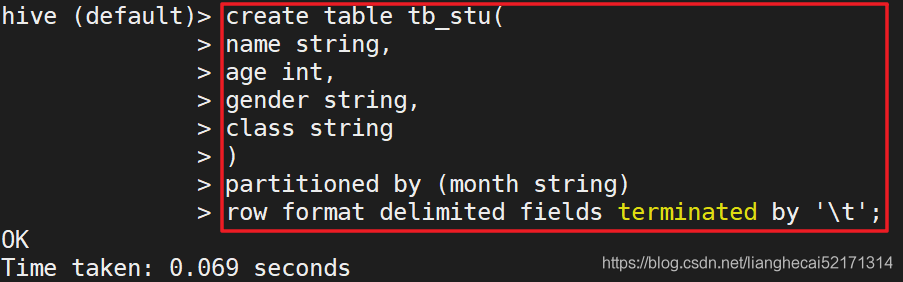
Hive建表与分区
1 | create table student(id string,name string) partitioned by(classRoom string) row format delimited fields terminated by ','; |
普通的建表与mysql差不多,多了个 row format delimited fields terminated by
在hive目录中看到的有日期的是分区表如下:
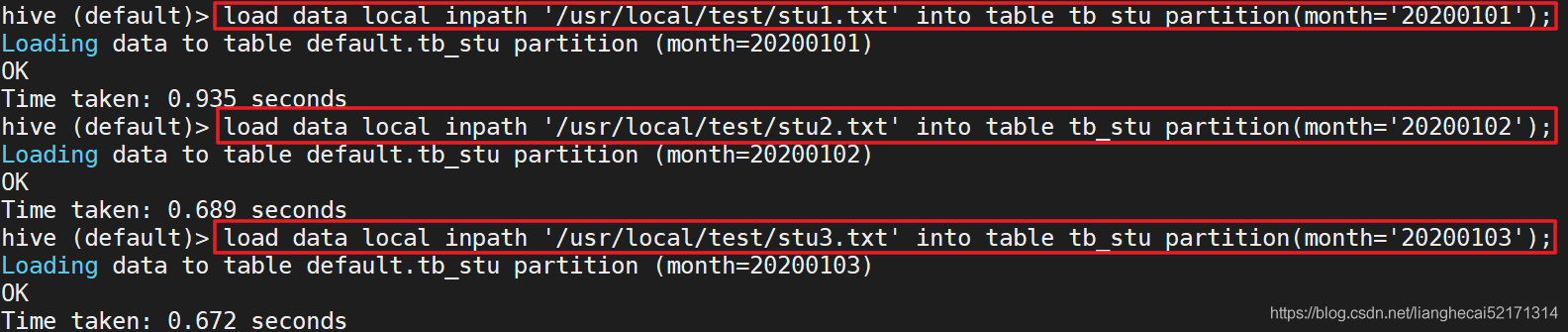
查看数据
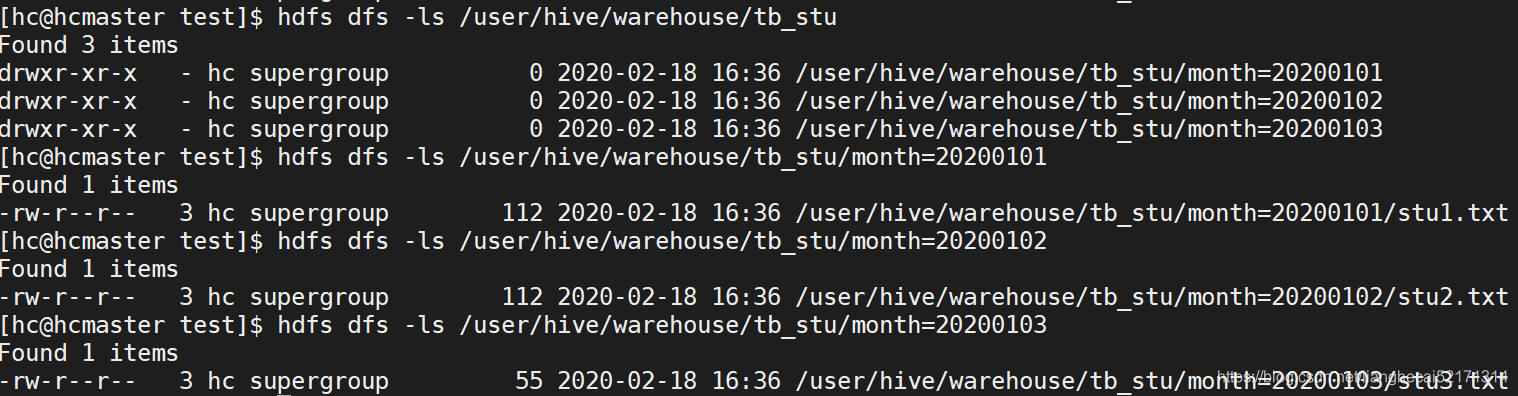
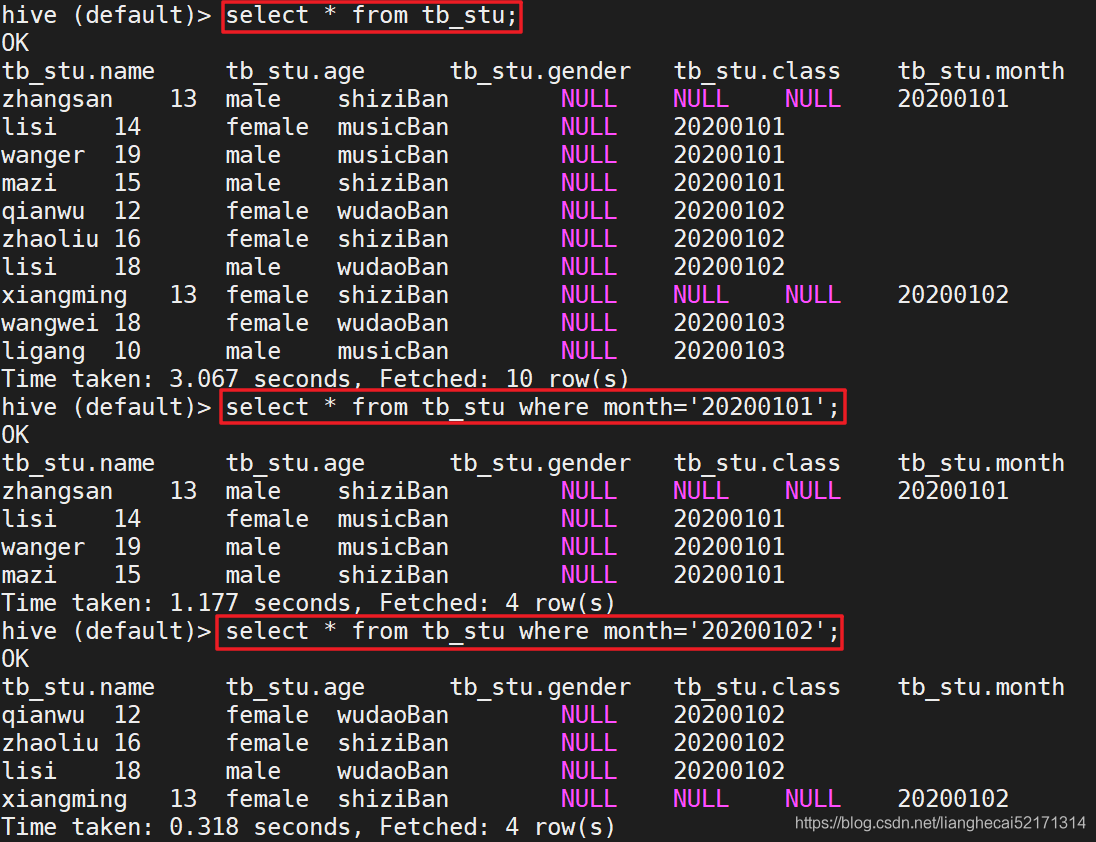
更多分区内容:https://blog.csdn.net/lianghecai52171314/article/details/104671599
hive操作
load hive加载数据:Load可以从本地文件系统加载,也可以从hdfs上加载。从本地系统上加载是复制,从hdfs上是移动。最终到的地点就是表的文件夹下。这就是官方推荐的加载数据的方式,即清洗数据成为结构化文件,再用Load语法加载数据到表中
Insert:在空文件中插入一条数据都需要几十秒,所以insert并不是像普通关系型数据库一样的用法,它用到的场景是insert+select。也就是把查询返回的结果插入到另一张表中。
insert into table select statement... From tableselect 等与mysql类似
ETL就是去掉一些字段,拆分一些字段,生成新的表 create table as select。生成结果表也是这么操作
数仓实战-从原始数据、ETL、数仓、到报表
实时数仓与离线数仓的区别
一、技术栈上,离线一般hive spark hdfs等,实时flink kafka hbase
二、分层上,离线分层更多,实时相对减少
三、实效性上,实时更加实时,延时控制在秒级别
四、运维上,实时相对比较困难,其储存使用kafka ,不可查询,排查问题比较困难
五、业务需求上,离线多于实时。
我们从以下7个方面来对比离线数仓与实时数仓区别:
1.架构选择方面,离线数仓采用传统大数据架构模式搭建,而实时数仓采用Kappa架构方式搭建。
2.建设方法上两者都是采用传统数仓建模方法论。
3.准确性方面,离线数仓准确度高,实时数仓随着技术发展,准确度也比较高。
4.实时性方面:离线数仓统计数据结果一般是T+1,实时数仓统计结果一般是分钟级别、秒级别。
5.稳定性方面:离线数仓稳定性好、方便重算。实时数仓对数据波动比较敏感,数据重新计算时相对麻烦。
6.数据吞吐量方面,离线数仓吞吐量都很高,实时数仓随着实时技术发展吞吐量较高。
7.数据存储方面,离线数仓一般将数据存储在HDFS、Hive中,实时数仓一般将数据存储在Kafka、Hbase、Redis、ClickHouse中。
列式存储数据库
列式数据库和行式数据库只是在存储上有区别,数据展现上都是一样的,都是标准的行列结构。
https://www.jianshu.com/p/d1114dd4f77a
行存储
在行存储下,数据如下:
姓名 |
身份证号 |
检测机构 |
检测时间 |
结果 |
价格 |
|---|---|---|---|---|---|
| 彦祖 | 123512387 | 北京 | 2021-12-24 12:12:45 | 阴性 | 35 |
| 德华 | 213124157 | 上海 | 2021-12-22 12:12:45 | 阴性 | 20 |
| 路人甲 | 213123145 | 河南 | 2021-12-21 12:12:45 | 阴性 | 8 |
| 德华 | 213124157 | 广州 | 2021-12-29 12:12:45 | 阴性 | 23 |
| 彦祖 | 123512387 | 上海 | 2021-12-30 12:12:45 | 阴性 | 20 |
因为数据都是按行方式存储,所以在物理存储中,会以连续空间来存储数据,物理存储中,这些数据存储方式如下:
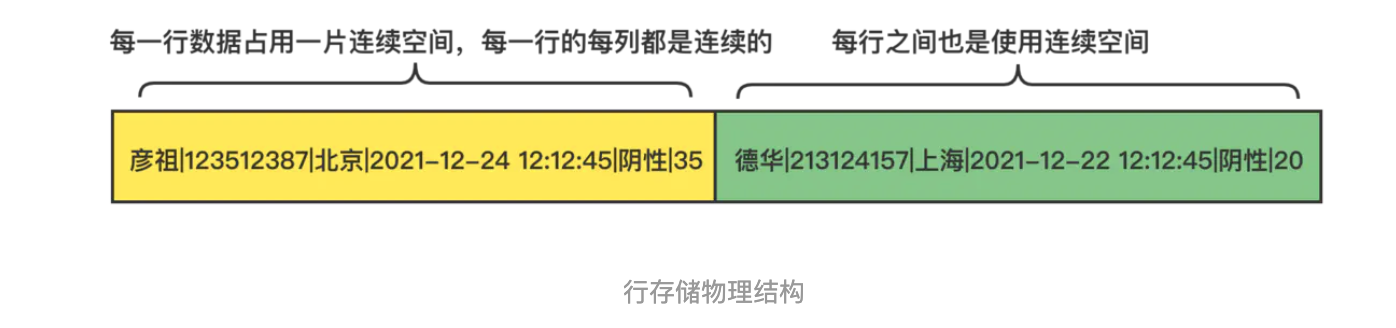
行存储优缺点总结
- 通过上面的分析,总结一下行存储的优缺点
优点:
1 | 1.连续空间对于插入/更新很方便 |
缺点
1 | 1.会查询出来很多不需要的列 |
列存储
姓名 |
身份证号 |
检测机构 |
检测时间 |
结果 |
价格 |
|---|---|---|---|---|---|
| 彦祖 | 123512387 | 北京 | 2021-12-24 12:12:45 | 阴性 | 35 |
| 德华 | 213124157 | 上海 | 2021-12-22 12:12:45 | 阴性 | 20 |
| 路人甲 | 213123145 | 河南 | 2021-12-21 12:12:45 | 阴性 | 8 |
| 德华 | 213124157 | 广州 | 2021-12-29 12:12:45 | 阴性 | 23 |
| 彦祖 | 123512387 | 上海 | 2021-12-30 12:12:45 | 阴性 | 20 |
同样的数据,物理结构如下:

列存储优缺点总结
- 通过上面的分析,总结一下列存储的优缺点
优点:
1 | 1.数据压缩比较有优势 |
- `缺点
1 | 1.每次查询时,都需要对查询到的列进行数据重新组装 |